PDF files are one of the most common online documents formats. In many cases, you will need to extract URLs from a specific pdf file. Whether this file is on your desktop or the web, if you are a Linux user, you have no easy GUI software options to facilitate this task for Windows users. And therefore, you have come to the right place!
As we mentioned previously, Linux has no or limited PDF software editors to extract text or links from it. But Linux has many rich commend shell better options. Those eager users of Linux like you certainly prefer to use command and bash shell solutions. So let us begin.
There are many terminal commands and options to get all links from pdf Linux. Some of them are ready to use and don’t need extra steps. Others need to install some additional libraries and packages. However, each method has its pros and cons. Let’s get started.
Using pdftotext
To be able to use pdftotext, we have to install poppler-utils:
$ apt install poppler-utilsBy using the pdftotext command, you can get a list of all URLs in a pdf file. You still need to merge it with some options and other commands such as grep, like this:
$ pdftotext -raw "filename.pdf" && file=`ls -tr | tail -1`; grep -E "https?://.*" "${file}" && rm "${file}"Here’s what the above command is doing:
- First, it creates the text version of the PDF document using
pdftotext. - After the text version of the PDF is generated, we run two commands. The first one is getting the newly generated file name using the
ls -tr | tail -1. - The second one is extracting the HTTP/HTTPS links using the
greptool. - Finally, we remove the file using
rm.
Note that the pdf file name is case-sensitive.

You can also pass grep -oE instead of grep -E to only print the URLs and not the whole line.
Let’s combine the above command and extract the links to write them to a file:
$ pdftotext -raw 1710.05006.pdf && file=`ls -tr | tail -1`; grep -oE "https?://.*" "${file}" > "${file}-urls.txt" && rm "${file}"
$ cat 1710.05006.txt-urls.txt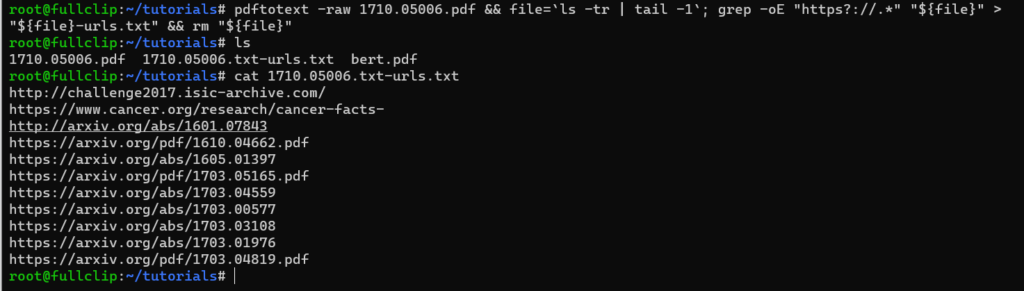
The newly generated text file that contains the links is named after the PDF document, the > "${file}-urls.txt" part of the command is responsible for that; you can change it to urls.txt for example.
If you want to test the above command but don’t have an example PDF document, you can download a sample here.
Related: How to Convert PDF Files to Images in Linux
Using Strings
You can also use the pre-built strings command and grep to do the same thing:
$ strings somePDFfile.pdf | grep http
However, as you can see, we will miss many URLs; the first method is the preferred one.
Using pdfx
Another alternative would be pdfx. But you need to install it firstly with easy_install or pip, or you will get a “command not found” message:
$ pdfx -v file.pdf | sed -n 's/^- \(http\)/\1/p'
Pdfx has many features and options that deserve to try, such as finding broken hyperlinks (using the -c flag), outputting the result as JSON, and online pdf files directly without downloading them.
If you already have Python installed, you simply use easy_install to install it:
$ sudo easy_install -U pdfxOr using pip:
$ pip install pdfxTo use it, simply pass the PDF path on your machine or the remote URL of the PDF document, as it’ll automatically download it:
$ pdfx <pdf-filename-or-url>Now let’s use the previous command on this PDF document:
$ pdfx -v 1710.05006.pdf | sed -n 's/^- \(http\)/\1/p'
There are many options to use, such as the -v flag for having all references, not just the PDFs, and -t flag to extract the pdf text, and -c flag to detect the broken links. You can also use it as a Python library or in a bash script.
Conclusion
While manually extracting some links from a pdf file is easy to do, the issue becomes more complex when the pdf file has hundreds of pages or multiple documents. Windows has many software solutions for such cases, but Linux has a more robust command shell. In this tutorial, we have passed by some methods to do that.
For me, I would go for the pdftotext option we showed as the first choice in this tutorial, good luck with your project!
Learn also: How to Extract Images from PDF in Linux.
Happy extracting!
